




Hybrid graph + vector
Semantic similarity and relational context queried together for precision neither achieves alone.
/ Enterprise Knowledge AI /
Enterprise Knowledge AI connects every document, system and data source into a single governed intelligence layer — and gives your people instant, accurate, source-grounded answers.
Why enterprise knowledge breaks down
Most organisations have more institutional knowledge than they can access. It sits in folders nobody navigates, wikis nobody reads, and in the heads of a few experts. The result: duplicated work, slow decisions, and knowledge walking out the door.
SharePoint, Drive, Confluence, Notion, email, local files — every team has its own system and they rarely connect.
Keyword search finds files. It does not answer questions. Users still read five documents — if the right one surfaces at all.
Outdated policies sit next to current ones. Ungoverned AI on top of that stack returns confident wrong answers.
Without attribution, confidence and an audit trail, AI answers are not acceptable in regulated or high-stakes environments.
Product definition
Semantic similarity and relational context queried together for precision neither achieves alone.
Multi-step retrieval and synthesis — not a single vector lookup — with gap detection and re-retrieval when needed.
Permissions inherited from source systems, enforcement at retrieval time, trust scoring and immutable audit logs.
Enterprise orchestration, model routing and operational patterns from the Thinkia Synapse platform.
Architecture
Connectors (OAuth/API), semantic chunking, OCR for scans, metadata preserved, incremental sync to control cost.
Vector search for similarity; knowledge graph for entities and relationships (e.g. supersedes, applies_to, owned_by).
Query decomposition, parallel retrieval, ranking, grounded synthesis, citations and confidence — with an agent loop for complex queries.
RBAC/ABAC, source trust scores, immutable audit trail, hallucination controls. EU AI Act–oriented human oversight and explainability; aligned with ISO/IEC 42001 and NIST AI RMF documentation.
Web app, Teams, Slack, browser extension, embeddable widget, REST/streaming API, OpenAPI and SDKs.
References to EU AI Act, ISO/IEC 42001 and NIST AI RMF describe product orientation and documentation patterns — not legal advice on your specific use case.
Retrieval loop at a glance
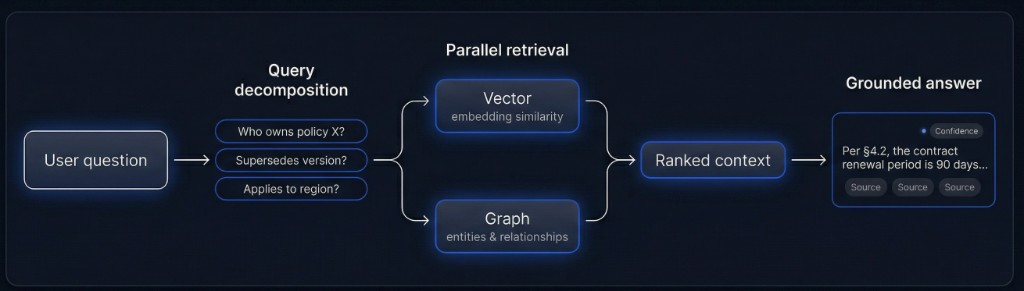
Complex questions split into sub-queries before retrieval to cut noise and token cost.
Vector and graph queries run together; results ranked, deduplicated and trust-weighted.
The model answers from ranked context only; claims link to source chunks with confidence.
Implementation path
Map sources, volumes, access models and priority use cases. Output: architecture brief and ingestion plan.
Deploy connectors, run chunking/embedding/graph extraction, configure access. Output: searchable, permission-aware base.
Evaluate retrieval quality, optional domain embedding fine-tune, set confidence thresholds. Output: validated quality report.
Pilot cohort, analytics on resolution and escalation, baselines for time-to-answer. Output: live system with measurement.
Expand sources and users, feedback loops, knowledge-gap reporting to improve documentation.
Connectors
OAuth and API connectors — content stays at the source; answers use only what each user may access.
Exact connector catalogue and deployment options are agreed per engagement.
Collaboration
Files & content
Systems & data
Metrics that matter
Targets and KPIs we agree per deployment — not one-size-fits-all numbers
<3s
Speed — time-to-answer (p95)
End-to-end for typical queries; complex agentic paths longer — see technical brief.
<20m
Speed — update propagation (p95)
Illustrative lag from source change to refreshed chunks for webhook-backed connectors; batch-heavy estates follow agreed schedules — tuned per engagement.
>90%
Precision — grounded quality
Typical post-tuning targets: precision@k and/or grounded-answer accuracy >90%, unsupported-claim rate <1% — validated on held-out sets per corpus.
>85%
Precision — recall & coverage
Recall@k and corpus coverage goals usually >85% where the answer exists in sources — measured with eval harnesses, not vanity benchmarks.
50–70%
Cost — vs naive RAG
Typical range when routing, caching, chunking and compression are enabled — illustrative, not a guarantee.
Audit-ready
Traceability — compliance trail
Query, sources, model and confidence logged for compliance workflows.
Comparative analysis
Microsoft 365 is one baseline; many estates still run a patchwork of search, wikis and DIY RAG — illustrative patterns, not vendor-specific claims.
| Factor | Copilot for M365 | Typical enterprise pattern | Enterprise Knowledge AI |
|---|---|---|---|
| Source coverage | Microsoft ecosystem focus | Fragmented search and portals across systems. | Broad connectors across enterprise sources |
| Knowledge graph | No relational reasoning layer | Keyword search without graph+vector multi-hop path. | Graph + vector hybrid for multi-hop questions |
| Model choice / BYOK | Azure OpenAI path | Scattered keys and chat tools; uneven policy. | Multi-model routing and BYOK options |
| Deployment | Cloud service model | SaaS sprawl; no single governed boundary. | Private, hybrid, or cloud—one governed layer |
| Commercial lens | Often per-seat in M365 narrative | Siloed licences; fragmented TCO story. | Packaging agreed per engagement |
Deployment options
Same governed knowledge layer — you choose where data, indexes and inference run, from air-gapped to fully managed cloud.
Full deployment inside your estate — indexes and optional self-hosted LLMs stay on your network. Maximum control for regulated and public-sector use.
Run in your AWS, Azure or GCP tenant: data and residency in your boundary, with Thinkia-managed deployment, upgrades and monitoring.
Thinkia-operated environment, EU-first by default. Fastest path to pilot with connectors to your systems over OAuth — no customer infra to run.
FAQ
Connectors detect changes on the next sync (webhook or schedule). Updated content is re-chunked and re-embedded; deletions remove index entries and revoke access immediately. Historical answers can be flagged in logs when sources change.
Yes, when both are connected and the user is entitled to both. The graph links entities from systems of record to documents and messages so answers can span contract language and operational data.
Depends on corpus size and source API limits. Indicative: smaller corpora in hours; very large corpora in weeks with parallel pipelines. Incremental sync keeps steady-state cost down — details in the technical brief.
The system is designed to answer from retrieved, permissioned context. When evidence is thin or missing, you get lower confidence, explicit gaps or a clear “not enough in the sources” style outcome — not a confident guess. Thresholds and escalation behaviour can be tuned for your risk posture.
Enterprise deployments are scoped so your corpus is not mixed into a shared training pool for public models. With BYOK or on-prem inference, model providers are chosen under your agreements. Exact terms belong in contract and DPA — we’ll map this in pre-sales and security review.
No. EU AI Act, NIST AI RMF and ISO/IEC 42001 references describe product orientation and documentation patterns — not a legal classification of your use case. For regulatory positioning, use your counsel and see Thinkia’s governance pages for general orientation.
Conflicting claims are surfaced with both sources cited and the conflict flagged. The system does not silently pick a winner — resolution stays with the knowledge owner. Conflict rate can be tracked as a quality signal.
By default, routing uses smaller models for simple queries and larger ones for complex reasoning. BYOK lets you bring your preferred providers. On-prem deployments can use approved open-weights models.
The index is built with source identity and entitlements. At query time, retrieval and synthesis only use chunks the caller is allowed to see — the same rules as in SharePoint, Confluence, Drive or your source of truth. If a user cannot open a document in the source system, it should not appear in their answer context.
Typical patterns are private tenant, hybrid (data and index on your side, optional cloud orchestration) or managed cloud — depending on residency, network and procurement constraints. The technical brief outlines deployment assumptions; we align the target architecture in discovery.
Common connectors include Microsoft 365 / SharePoint, Confluence, Google Drive, and similar document stores, plus APIs and internal repositories. Custom or legacy systems usually integrate via API, export or a dedicated connector plan. Priority sources are agreed in the ingestion roadmap.
Get started
Tell us about your sources, access model and teams. We’ll come back with a clear next step — orientation, scope for a pilot, or pointers to governance — with no hard sell.